-
Transformer EncoderML engineer/NLP 2022. 12. 31. 01:00반응형
🕓 6 mins read
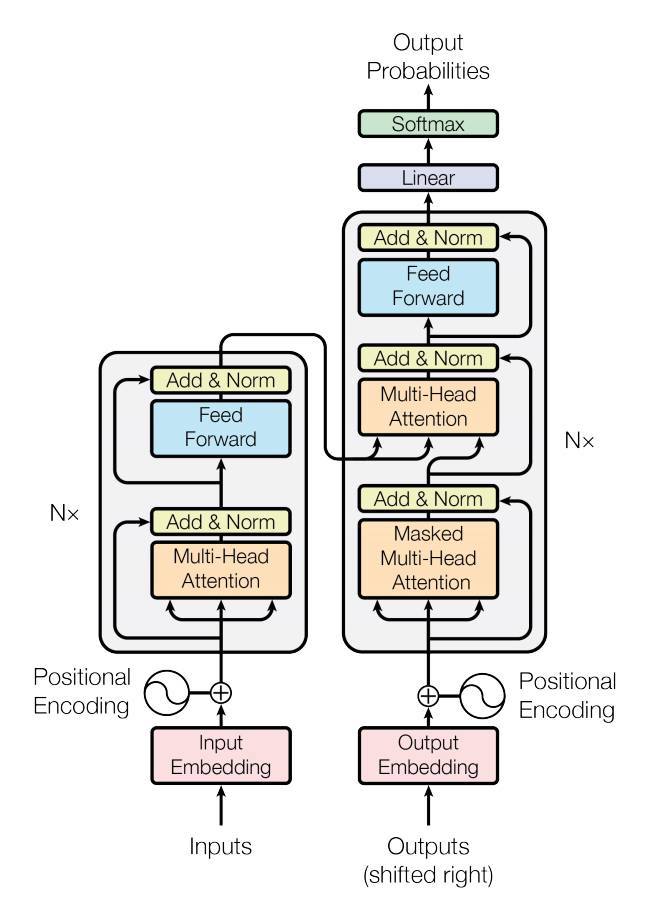
By the time anyone has reached this post, chances are you already know pretty much all about Transformer models.
It's no wonder since the paper Attention is all you need is already an old paper from 2017, which means it's pretty ancient in this field. Well I take should take that back. It's not that ancient.. considering how not much has changed in the seq2seq model paradigm. (GPT3, chatGPT and all that hype around big language models is still using Transformers architecture)
Attention Is All You Need
The dominant sequence transduction models are based on complex recurrent or convolutional neural networks in an encoder-decoder configuration. The best performing models also connect the encoder and decoder through an attention mechanism. We propose a new
arxiv.org
(Exported old 2018-10-27 post from my github page. w.t. some revisions)
So the point of this post is ..
It's pretty much a self record of how I read this paper in the past. (I know this post was initially written in 2018, and it's already the end of 2022 🤪)
To no surprise, I wasn't even using pytorch back then, it was all keras and tensorflow owning the industry.
(This post is about how I ported a tensorflow model into keras wrapper)For some of you, this may serve as a pythonic(?) guide through how the model's implementation works.
IF you are one such,
I dont' want to dig deep in to all the nuts and bolts, but still want/have to know the details...
I've seen the huggingface model implementation, but can't really grasp what it looks like in real life..
May be I want to try implementing BERT in keras/pytorch/tensorflow my self...# Transformer Encoder
Transformer encoder is composed of the following major parts.
(This is the main building block of the transformer model architecture)1. Positional encoding
2. Multihead attention layer
2.1 Scaled dot product attention
3. Pointwise feed forward layer
4. Auxiliary features
4.1 Dropout
4.2 Layer normalization
4.3 Residual connectionI won’t be going as far into covering all of the above, but What I will do is to look over the details of the code for 1., 2. and 3..
Hopefully, anyone who has read this would know enough to reimplement this in any language of their tastes. Maybe C/C++, for faster inference on cheap desktops without graphic cards.
Full code for this post is available at naubull2/keras-aux
## Positional encoding
def get_pos_seq(seq_input): """Get position offsets for each time step Create a tensor of [0, 1, 2, 3...] in the batch form, for later positional embedding vector lookup. """ T = tf.shape(seq_input)[1] pos = tf.tile(tf.expand_dims(tf.range(T), 0), [tf.shape(seq_input)[0], 1]) return pos def positional_encoding(max_len, d_emb): """Position encoding weight matrix Directly computed by sin(pos/(1e4^2i/d)) for 2i cos(pos/(1e4^2i/d)) for 2i+1 returns a weight matrix of shape [max_len, d_emb] """ pos_enc = np.array([ [pos / np.power(10000, 2 * i / d_emb) for i in range(d_emb)] for pos in range(max_len)]) pos_enc[:, 0::2] = np.sin(pos_enc[:, 0::2]) # dimension 2i pos_enc[:, 1::2] = np.cos(pos_enc[:, 1::2]) # dimension 2i+1 return pos_encThe function get_pos_seq() is pretty straight forward. We are creating an exact same shaped tensor filled with the offsets of the sequences.
Then the function positional_encoding() will create a weight matrix of the shape <max_len, d_emb>, which will be the positional embedding matrix for each position offset of an input sequence. The weight matrix is given by the following equation, as mentioned in the paper.
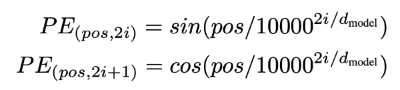
## Scaled-dot-product attention
class ScaledDotProductAttention(): """Scaled Dot Product Attention Introduced in https://arxiv.org/pdf/1706.03762.pdf """ def __init__(self, n_units, dropout=0.1): self.scale = np.sqrt(n_units) self.dropout = Dropout(dropout) def __call__(self, q, k, v, mask): # Scaled mat-mul on Q, K attn = Lambda(lambda x: K.batch_dot(x[0], x[1], axes=[2, 2]) / self.scale)([q, k]) # Assumption: 0 are used for padding sequences if mask is not None: # mask for softmax and future blinding paddings = Lambda(lambda x: (-2**32 + 1) * (1-x))(mask) attn = Add()([attn, paddings]) attn = Activation('softmax')(attn) attn = self.dropout(attn) outputs = Lambda(lambda x: K.batch_dot(x[0], x[1]))([attn, v]) return outputs, attnAs given in the paper, we will create an API for the following equation.
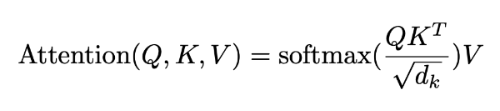
The first line of the function should give us the Q*K^T where K.batch_dot will compute the following.
q of shape <N:batch, T:length, d:dimension> k of shape <N:batch, T:length, d:dimension> Output shape = <N, T, T>As you can see, K.batch_dot(q, k, axes=[2, 2]) results in dot product along axes 2 of q and k. You can refer to Keras’s document for more examples of how K.batch_dot works.
Then, we add a mask for softmax activation. This line of code will add a huge negative value(precisely -2**32 + 1, stands for negative infinity) for the zeros and 0 for the ones.
What this does is to make the e^x value to converge to zero, so the softmax activation would turn it to zero.
In other words, NO ATTENTION.
Finally, we would dot product the softmax normalized attention matrix to the V matrix,
attn of shape <N, T, T> v of shape <N, T, d> Output shape = <N, T, d>Again, K.batch_dot will dot product attn and v accordingly, where v is the input matrix it self in the case of self-attention(In fact, q, k, v are all the same).
## Multi-head attention
Although it seems an awful lot of complications, we’ve already done all the computing in scaled-dot-product section.
As this section’s code is quite long to follow, I’ll skip the initialization and jump right in to the tricky parts, disecting each snippets of codes.
class MultiHeadAttention(): def __init__(self, n_head, n_units, dropout): ... Skipped def __call__(self, q, k, v, mask=None): n_head = self.n_head Q_ = self.Q_layer(q) # [N, T_q, n_head*n_units] K_ = self.K_layer(k) V_ = self.V_layer(v) def split_heads(x): input_shape = tf.shape(x) x = tf.reshape(x, [input_shape[0], input_shape[1], n_head, self.n_units]) x = tf.transpose(x, [2, 0, 1, 3]) x = tf.reshape(x, [-1, input_shape[1], self.n_units]) return x Q_ = Lambda(split_heads)(Q_) K_ = Lambda(split_heads)(K_) V_ = Lambda(split_heads)(V_) ... SkippedIt’s mostly reshaping the matrices and connecting the computational layers we’ve created.
First, we start off by linear transformation on each Q, K, V matrices. In the initialization, I’ve used ReLU activation, but linear transformation without the activation worked fine for the sizes of the data I’ve managed to get my hands on(though I doubt it’d work well on large dataset, as it would quickly overfit to the train set).
Then, we split each matrices, in the direction of the hidden dimension.
x of shape <N:batch, T:length, d:dimension> x of reshaped : <N, T, h:number of heads, d/h:split dimension> x of transpose : <h, N, T, d/h> x of reshaped : <h*N, T, d/h>As we split and merged each head, the input for the following computational graph becomes the same as dividing each batch instances into smaller batches.
The purpose of this split & merge technique is to perform scaled-dot-product attention on the different sub-sections of the dimensions accordingly(The authors of the paper calls this as “multi-head”).
class MultiHeadAttention(): def __init__(self, n_head, n_units, dropout): ... Skipped def __call__(self, q, k, v, mask=None): ... Skipped if mask is not None: mask = Lambda(lambda x: K.repeat_elements(x, n_head, 0))(mask) head, attn = self.attention(Q_, K_, V_, mask=mask) def merge_heads(x): s = tf.shape(x) x = tf.reshape(x, [n_head, -1, s[1], s[2]]) x = tf.transpose(x, [1, 2, 0, 3]) x = tf.reshape(x, [-1, s[1], n_head * self.n_units]) return x head = Lambda(merge_heads)(head) ... SkippedThen we apply the masked scaled-dot-product attention we created earlier, and merge the head back into the shape the original Q_(<N, T, n_head * n_units>) had.
class MultiHeadAttention(): def __init__(self, n_head, n_units, dropout): ... Skipped def __call__(self, q, k, v, mask=None): ... Skipped outputs = self.linear_out(head) outputs = Dropout(self.dropout)(outputs) # Residual connection outputs = Add()([outputs, q]) # Layer norm outputs = self.layer_norm(outputs) return outputs, attnFinally we apply another linear layer, pointwise feed forward, to restore the outputs into the original input shape.
As the paper suggested, I used two convolution with kernel size 1, with ReLU activation in between.
<N, T, n_units>
And to wrap it all, add a residual connection and the layer normalization.
That’s it for this post and you should be good to implement your own transformer encoder, and with enough data to train on, you can also make an attempt on BERT as the paper only require transformer encoders(Only, meaning multiple layers of transformer, with huge computing power requirements).
반응형'ML engineer > NLP' 카테고리의 다른 글
[업계 이야기] chatGPT 와 LLM에 대한 생각 (0) 2023.02.19 [02] Korean Language Model - 데이터 전처리 (1) 2023.02.04 [01] Korean Language Model - 데이터 수집 (1) 2022.12.31